.svg)

Building a Question Answering System Part 1

Welcome to the first part of our blog series, where we’ll show how you can build end-to-end AI applications quickly and with less fuss using Forte.
Part 2 in the series — Building a Question Answering System Part 2: Document Retrieval — is now available.
In this post, we will start to build a Q&A system that produces interesting answers by utilizing the CORD-19 dataset, which contains over 190,000 scientific and medical papers from the National Institutes of Health (NIH). To give you a sense of what the completed Q&A system can do, here are some sample questions and responses:

The full Q&A system contains three high-level steps; this blog post will show how to build and test the first step (Query Understanding). We’ll cover the second and third steps in our next blogs!
1. Query Understanding: the first step in Q&A, where the system extracts the core elements that make up the question or re-formulates the question into a standardized format to be used by the subsequent steps.
2. Document Retrieval: after obtaining the core content of the question, the next step is to identify a few documents that may contain the answer from a large document pool. This step should be done in an efficient manner to reduce the computational load for the next steps.
3. Answer Extraction: with only a small number of documents, the system can afford to use more sophisticated methods to find a short phrase or sentence that answers the user’s question directly and succinctly.
The diagram below shows the three steps with examples. The rest of this blog post will dive into implementing query understanding with Forte.
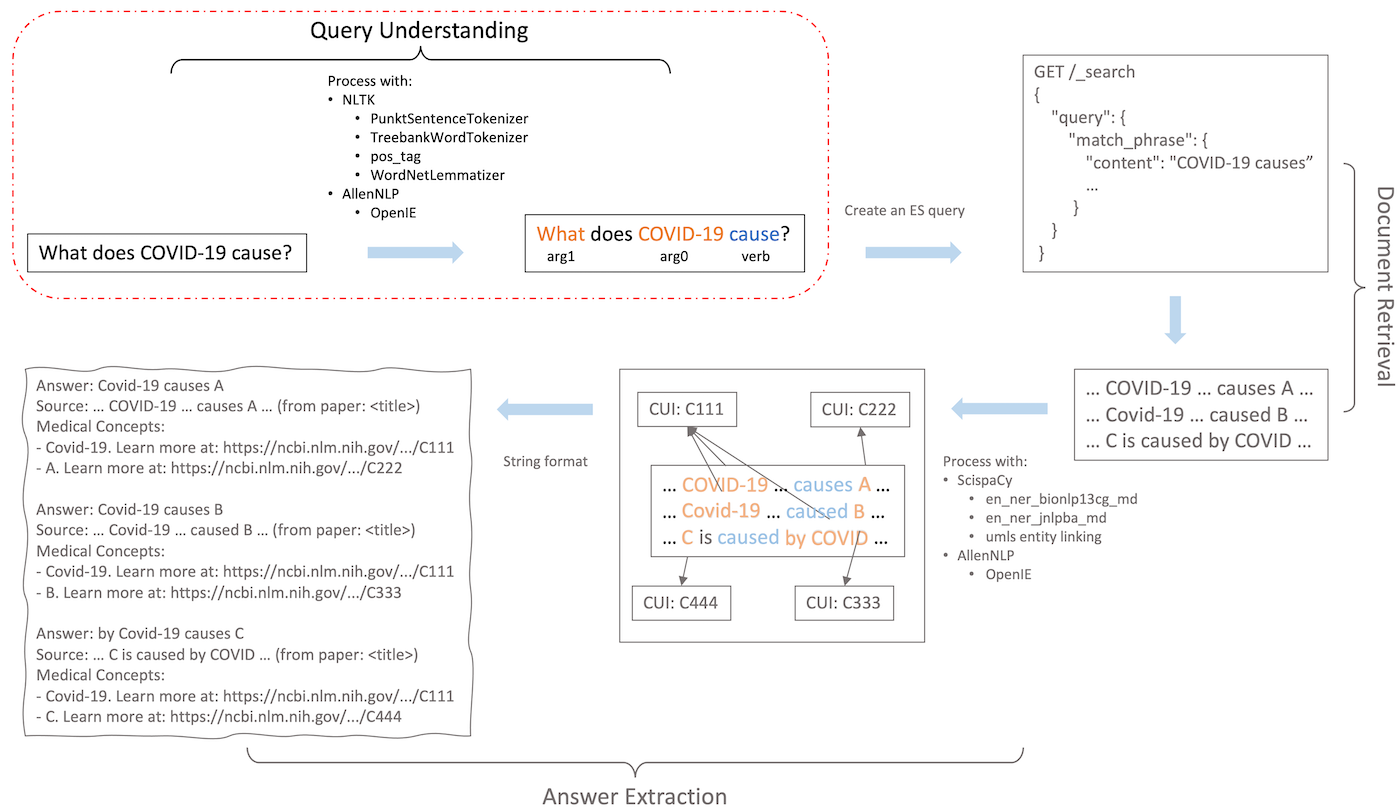
Query Understanding
Query Understanding is the process by which a Q&A system tries to understand the intent of the user’s question and translate it into a data format that can be recognized by subsequent steps. This step splits long questions into suitable units, canonicalize the input, and more importantly, find out what the user is trying to ask. The processed question can then be rewritten into queries for document retrieval and answer extraction.
Typically, the system analyzes the user’s input question by annotating basic language features using word segmentation, Part-of-Speech tagging and word lemmatization. These steps can help us find out the basic units (words) of the question and reduce the variations of word forms. For example, we can convert “causes” to “cause”, and “does” to “do”.
We can further analyze the semantic roles to understand the structure of the question. For example, given the question “What does COVID-19 cause?”, the semantic role analysis will reveal that “cause” is the main predicate we should focus on, “COVID-19” is the cause, and the wh-word (interrogative) “what” is the “effect” of “COVID-19”. This information tells the Q&A system that the user is looking for the effect of COVID-19.
Finally, we will store all the processed results, which can later be used to construct a structured query. The structured query can encode richer structure than the original question, such as semantic relationships among the words (Fig. 2) or query operators between the keywords (e.g., two keywords must appear together in less than 10 words). Such structured information can be helpful for finding the exact answer in the subsequent document retrieval and answer extraction steps. Forte will help you store these processed results so you can reuse them when needed.

Forte makes it easy to implement query understanding by combining two completely different NLP frameworks: NLTK and AllenNLP. In the following code snippet, NLTK is used for sentence segmentation, word splitting, part of speech tagging and lemmatization. AllenNLP is used for semantic labeling. Even though NLTK and AllenNLP use completely different input and output formats, Forte makes it a seamless experience to connect them together.
The entire query understanding pipeline is encapsulated in the code snippet below.
Environment Setup
Python environment (Conda or Python venv)
Option 1: Using Conda
Option 2: Using Python venv (requires python >= 3.6)
Install dependencies
Build a Forte pipeline that performs query understanding
The following instructions are also available in an interactive IPython notebook.
Create an empty Pipeline object
A Pipeline object in Forte controls the execution of sub-tasks and manages the resources needed to perform them. To get started, we first create a new empty “Pipeline” instance here and will gradually add processing steps after it.
Attach a reader to the pipeline
All pipelines need a reader to read and parse input data. To make our Q&A pipeline read queries from the user’s command-line terminal, use the TerminalReader class provided by Forte. TerminalReader transforms the user’s query into a DataPack object, which is a unified data format for NLP that makes it easy to connect different NLP tools together as Forte Processors. For more information on DataPacks, see our Forte blog post.
To run the pipeline consisting of the single TerminalReader, call process_dataset which will return an iterator of DataPack objects. The last line in the following code snippet retrieves the first user query from the TerminalReader.
The following for loop will run forever prompting for queries and echoing them.
Add a pre-built Forte processor to the pipeline
A Forte Processor takes DataPacks as inputs, processes them, and stores its outputs in DataPacks. The processors we are going to use in this blog post are all PackProcessors, which expect exactly one DataPack as input and store its outputs back into the same DataPack. The following two lines of code shows how a pre-built processor NLTKSentenceSegmenter is added to our pipeline.
When we run the pipeline, the NLTKSentenceSegmenter processor will split the user query into sentences and store them back to the DataPack created by TerminalReader. The code snippet below shows how to get all the sentences from the first query.
Add more NLP processors to extract language features such as POS (Parts of Speech), Lemma and SRL (Semantic Role Labeling)
This step involves composing more Forte processors to extract useful features from the user query. First, we make use of three NLTK processors to perform the following standard NLP operations.
- NLTKWordTokenizer iterates over all Sentence entries in the DataPack using DataPack.get(Sentence), tokenize the sentences, and create Token entries to store the tokens/words.
- NLTKPosTagger loops through all the Token entries and assign a value to the pos attribute on each of them.
- NLTKLemmatizer assigns a value to the lemma attribute on each of the Token entries.
Then, a more advanced deep learning powered AllenNLPProcessor is appended to determine the semantic relations between words. This processor loops through all the Sentence entries and creates PredicateLink entries that represents semantic relations between verbs and nouns. PredicateLink.get_parent() is the verb and PredicateLink.get_child() is the noun and PredicateLink.arg_type is the type of the relation. Recall the example we had earlier, the sentence “What does COVID-19 cause?” has two PredicateLink pointing from a parent to a child. Arg0 and arg1 are the two different relation types.
All the processor results are nicely organized and stored in DataPack and are easily accessible anytime.
Try different queries to see what this pipeline can do, here is an example:
Tip: nest the above for loop under for datapack in nlp.process_dataset(): to continuously prompt for new queries!
In this example, we have successfully identified the words and their canonical forms (e.g., the lemma for “does” is “do”). We have also identified the part-of-speech of these words, which allow us to identify the question word “what” by looking at the part-of-speech tag “WP” (short for Wh-Pronoun). The semantic role labels further help us find the main verb and indicate that the question is to find the “effect” of COVID-19.
Looking Forward
Query understanding helps to construct less ambiguous queries which can be used to find exact answers to user queries. In the next blog post, we will show how to quickly find relevant documents from a large corpus to answer questions posed by the user. You will learn to implement the other two core parts of the Q&A system, Document Retrieval and Answer Extraction, and understand how they work together to accurately search for answers from a large knowledge base containing 190k+ medical articles. Stay tuned!
Part 2 in the series — Building a Question Answering System Part 2: Document Retrieval — is now available. Part 3, Answer Extraction, is coming soon.

Why use Forte?
We hope you liked this guide to building a Q&A pipeline in Forte! We created Forte because data processing is the most expensive step in AI pipelines, and a big part is writing data conversion code to “harmonize” inputs and outputs across different AI models and open-source tools (NLTK and AllenNLP being just two examples out of many). But conversion code needs to be rewritten every time you switch tools and models, which really slows down experimentation! That is why Forte has DataPacks, which are essentially dataframes for NLP — think Pandas but for unstructured text. DataPacks are great because they allow you to easily swap open-source tools and AI models, with minimal code changes. To learn more about DataPacks and other time-saving Forte features, please read our blog post!
About CASL
CASL provides a unified toolkit for composable, automatic, and scalable machine learning systems, including distributed training, resource-adaptive scheduling, hyperparameter tuning, and compositional model construction. CASL consists of many powerful Open-source components that were built to work in unison or leveraged as individual components for specific tasks to provide flexibility and ease of use.
Thanks for reading! Please visit the CASL website to stay up to date on additional CASL and Forte announcements soon: https://www.casl-project.ai. If you’re interested in working professionally on CASL, visit our careers page at Petuum!


